Rendering
Getting a window to pop up is great and all, but it's not much of a video game without something to look at! Like I mentioned in the last chapter, I've added the metal-cpp library to the project, but the non-Metal APIs were very limited in their C++ support, which resulted in my platform code being written in Objective-C++. I suppose we'll soon find out how far we can get using metal-cpp before we have to fall back to using Objective-C++ for the Metal API as well.
3.1 Drawing to a Surface
I initially set out to create some surface to draw to, which lead me down the path of needing to create an MTK::View, which first required a window to be created. Now that I have a window, let's see if I can create the view. The view accepts two arguments: the frame (which I can re-use from the window creation) and the MTL::Device. Getting a device should be as simple as calling MTL::CreateSystemDefaultDevice(), so I'll add that and see if I can compile. Unfortunately I got a linking error:
Undefined symbols for architecture arm64:
"MTL::CreateSystemDefaultDevice()", referenced from:
-[AlfredoApplicationDelegate applicationDidFinishLaunching:] in AlfredoApplicationDelegate.mm.o
That's very unusual, since I got the metal-cpp sample programs running just fine using my own CMake configurations. Let me just peek into one of the samples and see if anything stands out. The very first thing I notice is these obscure #define calls at the top of the files:
#define NS_PRIVATE_IMPLEMENTATION
#define MTL_PRIVATE_IMPLEMENTATION
#define MTK_PRIVATE_IMPLEMENTATION
#define CA_PRIVATE_IMPLEMENTATION
The README.md file in metal-cpp calls out the requirement of the NS_ and MTL_ variants within the "Adding metal-cpp to a Project" section, and mentions the CA_ variant in case you want to use QuartzCore, but doesn't mention the MTK_ variant, which I assume is for MetalKit. I'll forego the MTK_ and CA_ defines for now, since my IDE says they are unused after pasting this block (which makes sense, considering I'm not using any QuartzCore or MetalKit headers yet).
Well I didn't get the same linking error, but unfortunately my build didn't even make it to the linking phase. Instead I'm now seeing a bunch of these types of compilation errors:
third_party/metal-cpp/Foundation/NSBundle.hpp:98:1: error: redeclaration of 'NSBundleDidLoadNotification' with a different type: 'const NS::NotificationName' (aka 'NS::String *const') vs 'const NSNotificationName _Nonnull' (aka 'NSString *const')
It appears that the metal-cpp library is not meant to be included in a project which already includes the Objective-C versions of the same libraries - the headers of each define the same names using incompatible types, and I'm not sure if I can work around that with more magical defines. If I import <Metal/Metal.h> instead of <Metal/Metal.hpp>, and use MTLCreateSystemDefaultDevice() rather than MTL::CreateSystemDefaultDevice(), then the program compiles and runs just fine.
There is theoretically a path forward in which my header files never include either <Metal/Metal.h> or <Metal/Metal.hpp>, but it might be confusing to put it into words. Let me give it a shot...
I was already planning to make a Renderer interface, which could be implemented for any number of rendering APIs, including an obvious MetalRenderer for Apple devices. The Engine class wouldn't care which type of Renderer it received, so it would never transitively include any Metal-related headers.
The problem is that the code for Alfredo has to coordinate a couple of things that are at odds with one another:
- Construct an instance of the theoretical
MetalRendererin order to pass it to theEngineconstructor, which means including theMetalRenderer.hheader, which itself would theoretically include<Metal/Metal.hpp>. - Initialize a
MTKViewto render to, which requires aMTLDevice, which requires the inclusion of<Metal/Metal.h>.
If I can figure out how to convert from the Objective-C type to the C++ type, then I might be able to forward-declare the classes that need to be passed across the MetalRenderer.h boundary (such as MTL::Device, I presume), and then only include <Metal/Metal.hpp> within MetalRenderer.cpp, such that it never gets included transitively by Alfredo's application code, but still gets compiled and used.
Quick aside: this is the type of bull crap that I absolutely hate about C++ programming. I know it's more of an issue with crossing language barriers here, but I hate having to babysit my header inclusions on the off-chance that different headers aren't compatible with one another.
I did a Google search for "metal-cpp cast from objective c", and came across this Reddit thread about the release of metal-cpp, which has a comment from the developer mb862 in which they describe the use of Objective-C's __bridge functionality to convert an Objective-C variable into a C++ variable of a different type. That sounds like exactly what I'm looking for.
I whipped up a new Renderer class (which I don't intend to keep), with a constructor that takes in a MTL::Device, except I've forward-declared MTL::Device within Renderer.h instead of including <Metal/Metal.hpp>. Then, within Renderer.cpp, I've included <Metal/Metal.hpp>, and implemented the constructor and destructor. In the constructor, I'm keeping the pointer around in a private _device field, calling _device->retain(), as well as logging out the _device->name(). In the destructor, I'm calling _device->release(). I have to be careful about memory ownership when crossing the language barrier, since Objective-C's automatic reference counting (ARC) doesn't work inside of C++.
Within AlfredoApplicationDelegate, I've imported Renderer.h, and added the following to the applicationDidFinishLaunching method:
auto device = (__bridge MTL::Device*)MTLCreateSystemDefaultDevice();
auto renderer = new Renderer(device);
delete renderer;
Somewhat surprisingly, the program compiled and ran successfully on the first try! The first log that my application spits out is Apple M1 Max, which is the name of the SoC inside of my laptop (and therefore also the name of its GPU)!
Now we need to initialize an MTKView so we have something to render to. I'll create one using the NSRect we used for our window size, and the Metal device that we just created. I'll also set its pixel format to MTLPixelFormatBGRA8Unorm_sRGB and its clear color to red, which is what the example project uses - I'll end up tweaking these for my own use cases later. Finally, I need to define my own implementation of MTKViewDelegate, and set it on the MTKView. The MTKViewDelegate provides a couple of methods: one to react to resizing events, and one to actually do all of your drawing logic whenever something calls [view draw].
According to the MTKView documentation, the view supports three possible drawing modes. The default mode automatically calls the drawing functions on a timer, apparently configurable using the preferredFramesPerSecond method, which defaults to 60 frames per second. Another mode is suitable for more traditional apps where you don't necessarily want to re-draw everything unless something actually changed. Finally, there is a fully manual drawing mode available, which I think I will use so that I can hook the rendering logic into my game loop.
For now though, I just want to see my configured clear color show up in my window. I created an AlfredoViewDelegate, which inherits from MTKViewDelegate, and passed a pointer to my Renderer into a new initWithRenderer initializer method. I then called renderer->draw() from the drawInMTKView method (which is called whenever something calls draw on the view).
Since the draw method doesn't actually exist on my Renderer class yet, I created it. For the time-being, this method will contain the logic to write GPU instructions to a command buffer, and submit that buffer to the GPU for execution. Command buffers are a feature of "modern" rendering APIs. Classical rendering APIs submitted instructions to the GPU as soon as you called the function to do so, and, at least in the case of OpenGL, required that you only called those functions from the main thread of the application. With the multi-core processors gaining in popularity, some smart people figured out that they could utilize multiple application threads to build of queue of commands to execute in the future with very little coordination between them. I don't actually have any sources for this history lesson, but that's my understanding. I have used multi-threaded job systems to render using OpenGL and Vulkan in the past, and I gotta say, it's much less tedious to implement using an API that already supports command buffers (like Vulkan). Even though the concepts are similar across different APIs, the actual code can be annoyingly different, so I'll basically just be figuring out how to make Metal do what I already know how to do in Vulkan.
So I need to create a MTL::CommandQueue so that I can get MTL::CommandBuffers to write to. I'll just create a _commandQueue instance variable for now, and call _device->newCommandQueue() in the constructor of my Renderer. This will allow me to create command buffers on demand, but apparently you don't write commands directly to the command buffer in Metal - instead you have to use a MTL::CommandEncoder. There are multiple flavors of encoders, but the one I'm interested in is a MTL::RenderCommandEncoder. Apparently getting an encoder is as simple as calling a function on the command buffer, but for a MTL::RenderCommandEncoder, I have to provide a MTL::RenderPassDescriptor.
In Vulkan I'm accustomed to manually managing every little thing, but apparently MetalKit's MTKView tries to streamline this process a bit. I can just call the currentRenderPassDescriptor() method and I'm given a descriptor that already contains the details of my pixel format and clear color that I set up earlier, but I'll need to pass my view into my draw() method. Honestly, I'm not sure I like this, but it certainly makes things easier right now, so let's roll with it.
Now that I have a command encoder, I could start submitting all sorts of commands to the GPU! I can't get ahead of myself though - I will be patient and just call endEncoding() on the encoder for now. The only reason I created the encoder at all was to encode the render pass descriptor (including my clear color and pixel format) to the command buffer.
The command buffer has a very convenient method on it: presentDrawable. In Vulkan, you have to deal with GPU-local semaphores so ensure that your command buffers for a given frame are fully executed prior to presenting the resulting image. According to the documentation for presentDrawable:
This convenience method calls the drawable’s
presentmethod after the command queue schedules the command buffer for execution. The command buffer does this by adding a completion handler by calling its ownaddScheduledHandler:method for you.
Metal tends to be much less verbose than Vulkan (by a LOT), but I didn't expect these types of convenience features!
All that's left to do is call commit() on the command buffer. The example program for metal-cpp also creates an NS::AutoreleasePool, which I means I should be thinking about this C++ code like it's Objective-C. I'll add it too.
alfredo/src/render/Renderer.cpp
void Renderer::draw(const MTK::View& view) {
auto pool = NS::AutoreleasePool::alloc()->init();
auto commandBuffer = _commandQueue->commandBuffer();
auto renderCommandEncoder = commandBuffer->renderCommandEncoder(view.currentRenderPassDescriptor());
// TODO Draw stuff
renderCommandEncoder->endEncoding();
commandBuffer->presentDrawable(view.currentDrawable());
commandBuffer->commit();
pool->release();
}
alfredo/src/metalkit/AlfredoViewDelegate.mm
The application compiles and runs, and the window is filled with the red color of success!
3.2 Making it Suck Less
There's a lot I don't like about this. Normally I'd just jump straight into refactoring, but I feel like I need to explain exactly what is so terrible about what I've done so far. Doesn't it work as-is?
![]()
First of all, my Renderer interface can't actually be accessed from the Engine class, since I've created it within Alfredo instead of Linguine. Since the game loop can't access it, I can't actually draw() as part of the loop.
Even if I were to move the Renderer class into Linguine, it can't compile, since it depends on Metal and MetalKit, which are only available inside of Alfredo (and Scampi). What I've actually created is a MetalRenderer, and you can't even invoke the draw method without passing in an MTK::View, which means I can't trivially create a Renderer interface within Linguine and have a MetalRenderer which inherits from it.
You might be asking yourself (or probably not), "How is the game loop rendering the red background if it doesn't actually have access to the draw() method?" The answer is simple: it's not! I'm still relying on the default drawing mode, which is automatically calling drawInMTKView 60 times per second. I'll just go ahead an set the drawing mode to manual by configuring my view, as per the documentation:
Running this actually doesn't draw the red background color at all, but if I just add a simple [view draw];, then the background shows up again - it's just not being re-drawn as part of my game loop yet.
I can easily whip up a Renderer interface in Linguine and invoke its draw() method inside my game loop. I can then rename my existing renderer to MetalRenderer and refactor it to take in the MTK::View as a constructor parameter instead of the device, since I can get the device from the view. I can rename my current draw() method to drawInternal() and invoke it from my AlfredoViewDelegate, and implement the actual draw() method to call _view.draw(). That seems unnecessarily roundabout, doesn't it?
- Engine game loop:
- Calls renderer->draw()
- Calls view->draw()
- Calls [viewDelegate drawInMTKView:view]
- Calls renderer->drawInternal()
- Actually do Metal stuff
This works just fine, and results in update() being called 120 frames per second, which is my laptop display's maximum refresh rate. I just happen to know (via the documentation) that the MTKView utilizes a CAMetalLayer, so I can disable v-sync by setting ((CAMetalLayer*)[view layer]).displaySyncEnabled = NO, which results in frame rates around 180 frames per second. That's down from the 370,000 FPS prior to invoking the renderer. Communicating with the GPU is expensive!
Unfortunately, it seems like I can't just do the Metal stuff within the renderer->draw() because I get some error messages when doing so:
2023-01-25 23:30:47.705 alfredo[24008:1057406] [CAMetalLayerDrawable texture] should not be called after already presenting this drawable. Get a nextDrawable instead. 2023-01-25 23:30:47.705 alfredo[24008:1057454] Each CAMetalLayerDrawable can only be presented once!
It appears that the call to view->draw() is doing more than just forwarding the call to drawInMTKView, and that's exactly what I don't like about using this MTKView. I've already established that I don't need its automatic draw() call scheduling, and the lack of visibility into what it's doing to manage its render pass descriptors and drawables drives me nuts.
I'm not entirely opposed to using it though - the boundary between the rendering logic and the surface which gets rendered to is always pretty blurry. In my Vulkan-based projects, I would often create surface "provider" objects, so that the renderer didn't need to know about any windows, widgets, or other non-Vulkan APIs. The problem with the MTKView is that I don't just present a fully rendered texture to the surface, but the view actually owns the textures that I need to draw to, so I end up requiring the view just to access the "drawables" (Metal's word for a screen-sized texture, I guess) so that I can draw to them.
I understand that the entire point of MetalKit is to provide the middleware between AppKit/UIKit and the Metal API, which should make it easier for developers to adopt Metal. I will admit that making my application render a red screen took significantly less code than the equivalent Vulkan application.
So I'm torn. For all of my distaste of the MTKView, this code works just fine. Not only does it work, but I haven't leaked any details about the Metal renderer into Linguine - it still just calls a single draw() method.
So I'll just keep moving forward. If I eventually find that using the MTKView actually prevents me from achieving some goal (rather than just encouraging bad code design), then I will circle back and start managing my own drawables and render pass descriptors. Funny enough, if I hadn't written out all of my thoughts here, I probably wouldn't have even questioned my decision to get rid of the MTKView, and spent a lot more time refactoring for no functional purpose.
The only other thing I want to call out is that I very much dislike having to forward-declare any metal-cpp (or metal-cpp-extensions) classes that happen to be required in my MetalRenderer header. I wouldn't mind so much if I only had to forward-declare the MTK::View class, since that's the only dependency that has to be passed into the renderer, but because C++ requires private member variables to be declared within the class declaration, then the header either needs to include <Metal/Metal.cpp> or forward-declare all of the types for my member variables - and because we need to include MetalRenderer.h from the AlfredoApplicationDelegate, we cannot transitively include <Metal/Metal.cpp> without breaking everything, as we've already established.
For the time-being, I'll be using the Pimpl Idiom (pointer-to-the-implementation) to work around the problem. There are several ways to go about it, but the version I'm going with is to declare and define a MetalRendererImpl class in MetalRenderer.cpp. This class contains all of the Metal-specific stuff that I don't want to pollute my header file with, and implements the draw() and drawInternal methods. Most importantly, it inherits from MetalRenderer. The MetalRenderer class doesn't actually implement anything except a static create(MTK::View& view) method, which returns an instance of MetalRendererImpl, as a pointer to a MetalRenderer interface.
MetalRenderer.h
#pragma once
#include <Renderer.h>
#include <memory>
namespace MTK {
class View;
}
namespace linguine::alfredo {
class MetalRendererImpl;
class MetalRenderer : public Renderer {
public:
virtual ~MetalRenderer() = default;
static MetalRenderer* create(MTK::View& view);
virtual void drawInternal() = 0;
private:
friend class MetalRendererImpl;
MetalRenderer() = default;
};
}
MetalRenderer.cpp
#include "MetalRenderer.h"
#include <iostream>
#define NS_PRIVATE_IMPLEMENTATION
#define MTL_PRIVATE_IMPLEMENTATION
#define MTK_PRIVATE_IMPLEMENTATION
#include <Metal/Metal.hpp>
#include <MetalKit/MetalKit.hpp>
class linguine::alfredo::MetalRendererImpl : public linguine::alfredo::MetalRenderer {
public:
explicit MetalRendererImpl(MTK::View& view) : _view(view) {
_device = _view.device();
std::cout << _device->name()->cString(NS::StringEncoding::UTF8StringEncoding) << std::endl;
_commandQueue = _device->newCommandQueue();
}
~MetalRendererImpl() override {
_device->release();
}
void draw() override {
_view.draw();
}
void drawInternal() override;
private:
MTK::View& _view;
MTL::Device* _device = nullptr;
MTL::CommandQueue* _commandQueue = nullptr;
};
void linguine::alfredo::MetalRendererImpl::drawInternal() {
auto pool = NS::AutoreleasePool::alloc()->init();
auto commandBuffer = _commandQueue->commandBuffer();
auto renderCommandEncoder = commandBuffer->renderCommandEncoder(_view.currentRenderPassDescriptor());
// TODO Draw stuff
renderCommandEncoder->endEncoding();
commandBuffer->presentDrawable(_view.currentDrawable());
commandBuffer->commit();
pool->release();
}
linguine::alfredo::MetalRenderer* linguine::alfredo::MetalRenderer::create(MTK::View& view) {
return new MetalRendererImpl(view);
}
There are ways to do this patten without the use of virtual functions, which can result in performance loss, but I can always come back and optimize later if it becomes a problem, since I like this type of implementation the most out of the other options.
3.3 Keeping up with iOS
Other than getting a blank app running in the simulator, I've been utterly neglecting iOS support. I tend to have a lot of tabs open in my web browser related to whatever I happen to be working on, and I never close them until I feel like I don't need them anymore. I've been able to close a ton of tabs containing documentation for Metal or AppKit as I've figured out how to get things working in Alfredo, but I still have a ton of tabs open that specifically relate to iOS, and I'm afraid to close those tabs until I get something working. I know it's silly, but that is my primary motivator for taking a pit stop from the rendering code.
I've been looking through a lot of examples on how to build iOS apps using CMake. I noticed back when I was setting up the build for Scampi that all of these examples contained files like Info.plist or Main.storyboard, which appear to be XML files. As far as I can tell, Info.plist is used to define metadata about the application itself - the bundle ID, name, version number, etc. The *.storyboard files seem to define metadata about specific "pages" within the application (I'm sure that's not the correct nomenclature).
The Info.plist contains an entry called UILaunchStoryboardName, which I think is a splash screen that is displayed as the UIMainStoryboardFile is loaded. The UIMainStoryboardFile, on the other hand, seems to be the entry point of the application itself.
Each storyboard can define a viewController and a view, each containing optional customClass (and other custom* properties). It is the view's customClass which I can set to MTLView. The viewController's customClass can be set to my own UIViewController implementation to control the view.
I had previously been relying on CMake's autogenerated Info.plist file, which is populated using a handful of MACOSX_BUNDLE_* properties. CMake's autogenerated Info.plist does not support setting the aforementioned UILaunchStoryboardName or UIMainStoryboardFile entries, but it does allow you to pass in your own Info.plist by setting the MACOSX_BUNDLE_INFO_PLIST property. So I'll just whip up my own Info.plist based on the one that CMake was previously generating for me, which I can copy out of my build folder. Then I should be able to use it by adding this to my CMakeLists.txt for Scampi:
set_target_properties(scampi PROPERTIES
MACOSX_BUNDLE_INFO_PLIST "${CMAKE_CURRENT_SOURCE_DIR}/Info.plist"
)
I'll then add the following entries to my custom Info.plist:
<key>UILaunchStoryboardName</key>
<string>LaunchScreen</string>
<key>UIMainStoryboardFile</key>
<string>Main</string>
Now I need to create my storyboard files. I'll create a resources/ directory inside of Scampi to hold these things. Looking through the examples on Github, such as this one from the ios-cmake project, these files are filled with cryptic id properties, and I'm not sure how unique they actually have to be. Instead of copying anyone else's files, I'm going to create an Objective-C iOS application within Xcode using the "Game" application template, and copy the files from there.
After doing so, it appears that the id's that were generated for my newly created project are actually identical to those in the ios-cmake example project. Oh well, I didn't waste too much time on that.
Next, I'll need to create my ScampiViewController class. The viewController's customClass in the default Main.storyboard file is called GameViewController, so I'll just change that to ScampiViewController instead. I copied the GameViewController.h and GameViewController.cpp files from the autogenerated Xcode project, and renamed them appropriately.
They reference a Renderer from the autogenerated project, but I'm just going to delete all of that. For now, I'm going to copy the render/ directory from Alfredo and see what breaks.
The build seemingly succeeded, but when trying to run the application in the simulator, it immediately crashes with the following log in Console:
*** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: 'Could not find a storyboard named 'Main' in bundle NSBundle </Users/jdriggers/Library/Developer/CoreSimulator/Devices/753F4927-BCF7-450D-9E12-749CBD46D956/data/Containers/Bundle/Application/96DC355E-3C1A-4DFE-8C7C-F473FE062EF6/scampi.app> (loaded)'
Seems obvious enough. My storyboards aren't being copied into the application bundle. After a bit of digging, I found this nice little CMake property called RESOURCE. Setting it to my storyboard files does indeed copy them into the bundle, but the application is still crashing with the same error.
I've got to admit I was stuck on this for a solid hour. I couldn't find any search results that appeared to be the same problem I was having. I wound up building the autogenerated iOS project in Xcode and inspecting the application bundle that it created, only to find out that it had no storyboards inside the bundle at all! This got me thinking, "I wonder if the storyboards are compiled into the application binary?"
Eureka! I've been using Ninja as my build generator this whole time, but setting the CMake configuration for the iOS build to use Xcode instead magically fixed it. It appears that Xcode does indeed compile the storyboards into the application binary.
That took more time than I wanted it to, but I did learn something. Unfortunately, the "screen" of the simulator is not red, which means nothing is invoking my MTKView's drawInMTKView method. Back in the logs, I'm seeing this error message:
That's very unexpected, but okay, let's add a window property to ScampiApplicationDelegate:
ScampiAppDelegate.h
#import <UIKit/UIKit.h>
@interface ScampiAppDelegate : UIResponder <UIApplicationDelegate>
@property (strong, nonatomic) UIWindow *window;
@end
Build, run, and onto the next thing. The app launches correctly, but the screen still isn't red. I'm going to resort to good old "printf debugging", which is a fancy way of saying "add more logs". I've added a logging abstraction so that I can use NSLog() from within the Engine class (which has no knowledge of platform-specific stuff). Likewise, from within Scampi or Alfredo, I can log platform-specific types, such as NSString* (or even NS::String* in my C++ files) without having to convert to a std::string or char*, which I would just have to convert back into a NSString* in order to log it using NSLog().
linguine/include/Logger.h
#pragma once
#include <string>
namespace linguine {
class Logger {
public:
virtual void log(const std::string& log) const = 0;
};
}
scampi/src/platform/NSLogger.h
#pragma once
#include <Logger.h>
namespace linguine::scampi {
class NSLogger : public Logger {
public:
void log(const std::string& log) const override;
template<class T>
void log(T log) const {}
};
}
scampi/src/platform/NSLogger.mm
#include "NSLogger.h"
#include <Foundation/Foundation.h>
void linguine::scampi::NSLogger::log(const std::string& log) const {
@autoreleasepool {
NSString *nsLog = [NSString stringWithUTF8String:log.c_str()];
NSLog(@"%@", nsLog);
}
}
template<>
void linguine::scampi::NSLogger::log(NSString* log) const {
NSLog(@"%@", log);
}
namespace NS {
class String;
}
template<>
void linguine::scampi::NSLogger::log(NS::String* log) const {
@autoreleasepool {
NSLog(@"%@", (__bridge NSString *)log);
}
}
After adding more logs, everything seems to be called in the expected order. It turns out I just hadn't set the pixel format and clear color for this new MTKView. Finally, the screen is red!
There is still more to be done, however. The app still isn't ticking the game loop, or interacting with Linguine's Engine at all, so I'll need to figure out how to accomplish that without blocking UI events, similar to what was required for Alfredo.
The main method for Scampi simply returns the result of UIApplicationMain(), but according to the documentation, that function never actually returns:
Even though an integer return type is specified, this function never returns. When users exits an iOS app by pressing the Home button, the application moves to the background.
Bad grammar aside ("When users exits"?), this actually makes sense in the context of iOS, and it's not surprising that there doesn't seem to be an equivalent stop method for the UIApplication as there was for Alfredo's NSApplication. My hunch is that the game loop on this type of platform isn't actually a loop at all, but a series of update notifications triggered by the system. That is to say, it is "event-driven".
Looking through the autogenerated Renderer class in the Xcode game template, my suspicion seems to be correct. They have an _updateGameState method, which is called by the drawInMTKView method:
- System calls view->draw():
- Calls [viewDelegate drawInMTKView:view]
- Calls [self _updateGameState]
- Followed by Metal stuff
Basically, this means my Engine class needs the capability to be "ticked" frame-by-frame by an external actor. I can go ahead and add that somewhat easily. I'll extract the inside of my game loop into a new tick() method, and invoke that on every iteration of the loop. I'll also need to extract all of these local timing variables into members of the Engine class so that they can be retained between tick() calls.
I need to actually create an Engine instance within Scampi, but that means I'll need to provide implementations of the platform abstractions. Because I now rely on the system to call drawInMTKView, I no longer need to forward the renderer's draw() calls to the view delegate, only to be redirected back to my drawInternal() method. Instead, I'll just move my Metal logic back into the draw() method and get rid of drawInternal(). That means the renderers for Alfredo and Scampi have already diverged from one another - a detail which we can hopefully decouple from the MetalRenderer later on so that they can share most of the important stuff. Since we want to rely on the system to call drawInMTKView, I'll also remove [_view setPaused:YES] from the view controller.
I've created some platform abstractions for iOS. IosInputManager and IosLifecycleManager are currently just stubs which do nothing. IosTimeManager is a direct copy of Alfredo's MacTimeManager. I previously mentioned the new logging abstraction, but just for completeness, Alfredo uses a MacLogger which just uses std::cout so I can just view its logs from my IDE (or the terminal from which I ran the binary). Scampi, on the other hand, uses an NSLogger which (obviously) uses NSLog(), which I can view through the Console app.
Now I can just construct an Engine instance and call tick() from drawInMTKView, and it should work!
It didn't work. Logs indicate that drawInMTKView is never getting called by the system for some reason, but I can't tell why. I've experimented with different configurations for the MTKView, including explicitly setting my preferred frame rate, but no cigar.
After spending entirely too long (probably about 45 minutes), I realized that my ScampiViewDelegate instance was a local variable inside of my ScampiViewController's viewDidLoad method. The application loaded successfully, called viewDidLoad as intended, but once that method returned, my view delegate went out of scope and so there was nothing to call drawInMTKView on at all! The view delegate is now a member variable of ScampiViewController so that it stays alive after viewDidLoad returns, and things are looking good! Well, mostly...
default 18:49:38.726087-0500 scampi update(): 60 fps
default 18:49:38.726087-0500 scampi update(): 60 fps
default 18:49:38.742749-0500 scampi fixedUpdate(): 50 fps
default 18:49:38.742749-0500 scampi fixedUpdate(): 50 fps
default 18:49:39.726079-0500 scampi update(): 60 fps
default 18:49:39.726079-0500 scampi update(): 60 fps
default 18:49:39.742747-0500 scampi fixedUpdate(): 50 fps
default 18:49:39.742747-0500 scampi fixedUpdate(): 50 fps
My app's logs are duplicated for some reason. I know my Engine instance isn't getting ticked more than intended, because the number of frames being reported per second reflects exactly what I intend. It's possible that I have two Engine objects floating around somehow, each being ticked the correct number of times.
This Stack Overflow post says that it's just a quirk with the Console app, and to restart it. So I did, and sure enough, my logs are no longer duplicated.
default 19:13:58.666493-0500 scampi update(): 60 fps
default 19:13:58.683195-0500 scampi fixedUpdate(): 50 fps
default 19:13:59.666167-0500 scampi update(): 60 fps
default 19:13:59.683145-0500 scampi fixedUpdate(): 50 fps
I'm not fully convinced that I'm absolutely required to rely on the event-driven draw calls. Ideally I can consolidate the two MetalRenderer classes into a single class belonging to a sub-project which Alfredo and Scampi can share. The only thing currently stopping me from doing so is the calling paradigm difference between the two drawInMTKView methods. For now, I'll just whip up a faux renderer implementation in Alfredo to forward the draw() call to the MTKView, which will call the MetalRenderer's draw() method from drawInMTKView (rather than drawInternal()). This will at least let me share a common MetalRenderer, and still allow me to dig deeper into the event-driven side of things later.
So I've created a new renderers/ directory at the root of my project, and created a metal/ directory within it. I copied Scampi's MetalRenderer into the new sub-project, and deleted Alfredo's MetalRenderer. I created a new MTKRenderer within Alfredo which just calls draw() on the MTKView, and adjusted the view delegates of both applications to call the draw() method of the (now shared) MetalRenderer. After fixing a couple of typos, both projects build and run successfully. As a quick sanity check, I changed the clear color of the MTKView to blue from within the MetalRenderer constructor. As expected, both applications now display a blue background.
3.4 Actually Drawing Something
This part can be really easy or really hard, depending on how I want to go about it. The metal-cpp sample programs tend to take the "really easy" approach, in which everything is hard-coded in order to achieve the desired result with the minimum amount of code possible. There is no "game engine", which means there's no entity system to represent an object within the world. Objects are not dynamically created or destroyed based on events that happen in the game. The positions are not manipulated as a result of calculations from a physical simulation. These samples each contain a single C++ file which does the absolute bare minimum required to illustrate how to do something using the Metal API.
I am obviously not trying to build a sample project for the Metal API; I am building a game engine which will have dynamic objects that need to be manipulated using higher level abstractions, far away from any of the code required to render those objects. My engine, however, does not yet have an entity system that can be used for such dynamic operations. So why should I build a renderer that can support such things? The answer to that question is obvious - so I can add the entity system later!
I'll start off with the simple hard-coded approach so I can learn more about the Metal API, and attempt to mold the renderer into something that makes sense for a dynamic game engine later. I'd like to talk about what needs to actually happen in order to draw something on the screen, but first I'll have to give some context for how GPUs work and how rendering APIs interact with them.
GPU Architecture
A GPU is a very different piece of hardware than a CPU. While CPUs are engineered to be suitable for general tasks, GPUs are specifically very good at floating-point operations, which is why you might see Nvidia or AMD throwing benchmarks in your face touting how many "flops" (floating-point operations per second) their hardware is capable of. Furthermore, while a CPU might have a handful of cores which can perform concurrent operations, dedicated GPUs might have hundreds or even thousands of cores capable of crunching numbers at a remarkable rate.
For a piece of hardware that specializes in floating-point operations, there is a wide breadth of variety in the GPU ecosystem. My desktop contains a dedicated Nvidia 3080ti "Founder's Edition" GPU, which has 10,240 cores and 12 GB of graphics memory. My laptop, on the other hand, contains an M1 Max SoC which has an integrated 32-core GPU, and shares its 64 GB of memory between the CPU and GPU. To complicate matters further, my iPhone 13 Pro contains an Apple A15 SoC, which has an integrated 5-core GPU and 6 GB of shared memory. All of these devices are currently considered to be "high end" in their respective markets, and yet they are drastically different!
Why such a big gap between them? They all serve different purposes, and each of them are tailored to be well-suited for those purposes. Fewer cores means more power efficiency, which is of paramount importance on mobile devices. A laptop has a much bigger battery than a cell phone, so you can get away with having more cores. Too many cores, and you end up having to leave your device plugged in all the time, which is a usability nightmare!
Dedicated GPUs contain their own memory, which is great for runtime performance. These GPUs are designed to render hyper-realistic graphics at high frame rates. The GPU never has to worry about competing with the CPU for memory, and can keep high-resolution textures in its memory, readily accessible to render many objects within massive worlds. The memory itself is also custom tailored for use with GPUs, providing additional performance for the floating-point-centric workloads that GPUs are used for, which would be poorly suited for the general-purpose workloads of a CPU. This dedicated memory has an up-front performance cost, since all of that data has to be uploaded to the GPU's memory before it can be used. This can be a multi-step process in which the CPU has to load textures from the disk into its memory, only to then upload that data to the GPU's memory via the rendering API. Modern rendering APIs have gone to great lengths to prevent that two-step data transfer, going so far as to allow the GPU to access data from the disk directly, depending on hardware capabilities.
Integrated GPUs share memory with the CPU. This has massive power efficiency benefits - not only is there less total memory which requires power, but there is no need to upload data into GPU memory. With the GPU sharing memory with the CPU, leading to memory starvation. Operating systems are designed to proactively kill applications that are using too much memory in order to protect the rest of the system. Obviously the biggest downside to using an integrated GPU is performance. Fewer cores and general-purpose memory can be huge bottlenecks when rendering complex scenes. This is why mobile games don't have the hyper-realistic graphics that are typical on PCs or consoles.
There are tons of games out there that don't require massive dedicated GPUs. Certainly the type of game that I am trying to build here won't need more than what a typical smartphone provides.
Shaders and the Rendering Pipeline
Shaders are programs which run on the GPU. Yup, that's it. Well, I guess it's a little more complicated than that.
Shaders get their name from their ability to calculate lighting, but have evolved to be much more than that. Modern GPUs support many different types of shader programs - some can generate geometry on the fly (geometry shaders), while others can do more generic computational work (compute shaders). Highly parallelized processing of floating-point numbers make GPUs naturally well-suited for machine learning algorithms, which are written using compute shaders. By far the most common types of shaders in game programming are vertex and fragment shaders.
Vertex shaders do calculations for every vertex within the geometry submitted to the GPU. The primary goal of most vertex shaders is to determine where on the screen any given vertex should be positioned. This process tends to use matrix multiplication to eventually convert from one "space" to another, and then another, until the final result is in "clip space", which is a 4-dimensional vector, containing X, Y, Z, and W components.
Every object drawn via the rendering API has all of its vertices processed by the vertex shader. The outputs of the vertex shaders are converted into "normalized device space", which is a 3-dimensional vector consisting of the X, Y, and Z components of the clip space coordinates, all divided by the W component, which should result in each component being between 0.0 and 1.0. Those outputs are then "rasterized", which converts the vertices from device space into "screen space"/"view space"/"window space" (depending on who you ask), which is a simple 2-dimensional vector consisting of X and Y components, which represent the number of pixels from the corner of the screen - in Metal, the top-left is {0, 0}. The output of the rasterizer is a set of "fragments", which are generally thought of as pixels on the screen, but that is technically inaccurate, since the set of fragments might not be equal to the set of pixels, depending on the parameters of your renderer. For any fragments that were generated between multiple vertices, the values that that rasterizer outputs are interpolated based on the distance from each of the surrounding vertices. Depth information may also be used in order to discard vertices which would be covered up by other vertices within a single fragment.
Fragment shaders do calculations for each of the fragments coming out of the rasterizer. Fragment shaders output the color information for a particular fragment, which is then written to a "render target" - typically a texture in the GPU's memory, which can later be presented to the screen.
Apple's documentation on the render pipeline for Metal does a better job at explaining the entire pipeline than I could possibly do.
It's worth mentioning that the word "pipeline" actually has a connotation in computer engineering and programming: it's a way of describing a multi-stage process in which all stages can be occupied by work at all times, much like an actual pipe, which can be completely filled with fluid at all times. Optimizing rendering performance can involve making sure that no stage of the rendering pipeline is starved of work. For the type of game I'm building, however, the GPU will likely be bored to death.
Shaders are written in a variety of different languages, but different rendering APIs require shaders to be written in specific languages. Naturally, Metal has its own Metal Shading Language that I'll have to learn. Since the concepts between the different rendering APIs are mostly the same, it's just a matter of learning the syntax, which isn't generally a problem for me (I did just use Objective-C for the first time in this project, after all).
In order to prevent the performance nightmare that an interpreted language would present on the GPU, shader programs are compiled prior to instructing the GPU to execute them. The compilation process can happen at a variety of stages, depending on the use case. The shaders can be compiled as part of your application's compilation process, but that could result in long build times for a highly iterative development flow. The metal-cpp examples appear to compile the shaders at runtime, which incurs a performance penalty every time you start up the application. I've seen other solutions compile the shaders on the first run, and then cache the results in a file which can be loaded on subsequent runs.
Modern rendering APIs require that you describe the entire pipeline you wish you use, including, but not limited to, which shaders will be used as part of that pipeline. You then activate the pipeline prior to your draw() calls. This explicit approach enables the use of lots of different types of pipelines (not just rendering pipelines).
GPU Memory Management
With GPUs having access to so much memory, rendering APIs have to provide ways to allocate chunks of that memory, copy contents to it from the CPU, and operate on that memory from shader programs. GPU memory might differ from general purpose memory, but it still ultimately stores binary data, just like any other memory. This data can be organized however the application sees fit, but there are common practices used with rendering pipelines, which rendering APIs tend to strongly encourage.
Vertex buffers are chunks of memory containing data about each vertex within some geometrical shape. These buffers can be organized in a variety of different ways, depending on the type of data being stored. For example, a vertex buffer containing positional data for a 3-dimensional object typically takes the form of an array of floats, with each vertex represented by 3 contiguous floats in the array - it's X, Y, and Z positions, relative to that object's center. Similarly, you might have a vertex array containing color data for that same object, in which each vertex is represented by 3 contiguous floats representing its red, green, and blue components, normalized between 0.0 and 1.0.
The rendering pipeline makes sense of the vertices by looking at them in order after they've been processed by the vertex shader. After the shader converts the vertices into clip space, it groups the vertices into triangles. The strategy the pipeline uses to do this can be configured via the rendering API. Those triangles are then passed to the rasterizer, and any pixel which is mostly within a triangle becomes a fragment, which gets passed to the fragment shader. Fragments can be discarded if the pipeline determines that the triangle was facing "away" from the screen, which is determined using a "winding order", also configurable via the rendering API (though each API has its preferred default). Imagine the three points of a triangle, and how you might represent those points within a vertex buffer. The order that you pass them in can ultimately determine whether the resulting triangle is visible or not.
Because the vertices are organized into triangles, there can be many duplicate vertices within the vertex buffer. For instance, a "quad" (any 2-dimensional object containing 4 points) is actually represented by 2 triangles. Each triangle shares 2 vertices with the other triangle. Index buffers allow you to define each unique vertex in the vertex buffer without duplication, and pass in an additional buffer containing the order of the vertices that should go through the pipeline. In a single triangle, or small geometries like a quad, you might end up breaking even, or even using more memory to represent your geometry using an index buffer in addition to your positional vertex buffer. As you require more and more duplicate vertices, or even add more vertex buffers to represent other features of your geometry (like colors or "normals" used for lighting calculations), the amount of data you save by using index buffers can be substantial.
Uniform buffers can be used within a pipeline to pass data that is common to all vertices and/or fragments, rather than duplicating the same exact piece of data within a vertex buffer for every single vertex. A common use case for uniform buffers is to provide the transformation matrix necessary to convert the vertices from "object space" (relative to the object's center) into clip space.
Textures are also common in rendering pipelines. In short, a texture is just a chunk of memory that represents color data. You typically define the size and color format of the texture via the rendering API, but how the GPU itself treats the texture is largely up to the GPU itself. Rendering APIs typically provide mechanisms to "sample" data from a texture. Screen space post-processing effects, such as "screen space ambient occlusion" (SSAO) as well as some anti-aliasing solutions, sample from a texture containing the already-rendered scene.
Putting It All Together
So what does all of that mean in the context of my renderer? On startup, I need to:
- Allocate vertex buffers, and maybe index buffers, containing my geometry.
- Write shaders which are capable of receiving my vertices and spit out the correct colors in the correct locations.
- Describe a pipeline which contains my shader programs.
Then every time my renderer is called, I'll need to:
- Activate my pipeline.
- Activate my vertex/index buffers.
- Make a "draw" call, which will utilize the currently activated pipeline and buffers.
The graphical equivalent of a "Hello world" application is the rendering of a multi-colored triangle, so I think that's an appropriate first step for my renderer. I should be able to pretty easily hard-code all of the required pipeline and buffer logic into the renderer, so I'll do that in order to figure out what Metal actually calls all of these concepts in its API.
Vertex Buffers
Buffer allocations are accomplished via the MTL::Device::newBuffer() method. Right off the bat, I've encountered a detail which I forgot to mention in my long-winded explanations: it's up to us to define how each buffer will be accessed and updated. Sometimes, you need a buffer that the GPU can write to and read from later, but the CPU doesn't need access to. Other times, you need a buffer which is written to from the CPU, but then read from by the GPU. Memory which both the CPU and GPU have access to can be expensive, depending on the hardware (either the CPU has to access the GPU's memory, or the GPU has to access the CPU's memory). An optimization for this use case is to:
- Create a temporary buffer which both the CPU and GPU can access.
- Fill the temporary buffer with the data from the CPU.
- Create a permanent buffer which only the GPU can access.
- Copy the contents of the temporary buffer into the permanent buffer.
- Destroy the temporary buffer.
This way, the buffer that gets activated each frame can only be accessed by the GPU, which results in better performance than the GPU reading memory owned by the CPU. This implementation is understandably tedious, so the Metal API has a MTL::ResourceStorageModeManaged option for buffers, in which the API encapsulates the creation of two underlying buffers (one on the CPU and one on the GPU), and provides a command to synchronize them explicitly. This option appears to forego destroying the temporary buffer, instead opting to just destroy it whenever you destroy the "container" buffer. Keeping the CPU buffer around could be beneficial in cases like uniform buffers which aren't updated every single frame, but are updated often enough that creating a temporary buffer over and over would be a waste. This is the storage mode used in the metal-cpp sample applications. Unfortunately, this storage mode is not available on iOS, which is a shame. For now, I'll just use MTL::ResourceStorageModeShared, which means the CPU and GPU will both have access to the buffer. This is not optimal at all, but will be good enough for my triangle.
I'll need to define a size for my buffers, so I need to go ahead and figure out what I'm going to put in them. I know a few things about the geometry that I want to render:
- It's a triangle, which contains 3 vertices.
- The vertex positions need to be represented in terms of "normalized device coordinates", which should be a 2-dimensional vector (in the form
{x, y}) ranging from{0.0, 0.0}(the bottom-left of the screen) to{1.0, 1.0}(the top-right of the screen). - Each of my vertices should be a different color, which can be represented as a 3-dimensional vector, where each value in the vector represents a single color component, ranging from
0.0to1.0(often in RGB form -{red, green, blue}).
I'll need to utilize a data structure capable of representing this data in a compact way so that I can later copy it into my buffers. However, I'll also need to keep in mind how the data is aligned in-memory, so that it is compatible with the shaders that I'll be writing later. Different types of data obviously take up different amounts of memory - we commonly refer to these data types as having a certain number of bits. Often overlooked, data types also have certain alignments that are optimized for use with certain CPU (or in our case, GPU) instructions. Game engines often use data types that take advantage of SIMD instructions - that is, "single instruction, multiple data". It's easy to imagine a CPU instruction which adds two numbers together, but modern hardware affords us single instructions capable of adding multiple pairs of numbers together at the same time! These vectorized instructions rely on the data to be available at memory addresses that are divisible by a certain number, often related to the size of the data vector (though that's not always the case). When you see the word "vector" in game engines, they are often referring to numbers which are capable of taking advantage of these types of instructions.
Rather than building my own types and writing my own assembly code to take advantage of specific instructions, I prefer to use types that someone else whipped up. I love getting into the nitty gritty, but that's pushing the limits of what I'm currently comfortable with. I'll eventually want to choose a library that is suitable for any platform, since I know the data types will be rampant throughout my engine code. For now, however, I'll just use the types available from including <simd/simd.h>, which is only available on Apple systems. The data types available to Metal shaders mirror what are available in this header (I think they might literally use this header in Metal, but don't quote me on that), so I know the alignments will match. This will unblock me for now so I can just draw this stupid triangle.
simd::float2 positions[] = {
{ -0.5f, -0.5f },
{ 0.0f, 0.5f },
{ 0.5f, -0.5f }
};
const size_t positionsDataSize = std::size(positions) * sizeof(simd::float2);
- The bottom-left corner will be halfway from the center to the left edge of the screen, and halfway from the center to the bottom edge of the screen.
- The top corner will be centered horizontally, and halfway from the center to the top edge of the screen.
- The bottom-right corner will be halfway from the center to the right edge of the screen, and halfway from the center to the bottom edge of the screen.
Native arrays don't provide bounds-checking, so let's use something safer:
std::array<simd::float2, 3> positions = {
simd::float2 { -0.5f, -0.5f },
simd::float2 { 0.0f, 0.5f },
simd::float2 { 0.5f, -0.5f }
};
const size_t positionsDataSize = positions.size() * sizeof(simd::float2);
Why does that have to be so wordy? Also, why do I have to explicitly say I have 3 elements when I've obviously constructed an array with 3 elements? Let's use something a little more dynamic:
std::vector<simd::float2> positions = {
simd::float2 { -0.5f, -0.5f },
simd::float2 { 0.0f, 0.5f },
simd::float2 { 0.5f, -0.5f }
};
positions.shrink_to_fit();
const size_t positionsDataSize = positions.size() * sizeof(simd::float2);
Screw it. Back to native arrays.
simd::float2 positions[] = {
{ -0.5f, -0.5f },
{ 0.0f, 0.5f },
{ 0.5f, -0.5f }
};
const auto positionsBufferSize = std::size(positions) * sizeof(simd::float2);
_vertexPositionsBuffer = _device->newBuffer(positionsBufferSize, MTL::ResourceStorageModeShared);
memcpy(_vertexPositionsBuffer->contents(), positions, positionsBufferSize);
_vertexPositionsBuffer->didModifyRange(NS::Range::Make(0, positionsBufferSize));
simd::float3 colors[] = {
{ 1.0f, 0.0f, 0.0f },
{ 0.0f, 1.0f, 0.0f },
{ 0.0f, 0.0f, 1.0f }
};
const auto colorBufferSize = std::size(colors) * sizeof(simd::float3);
_vertexColorsBuffer = _device->newBuffer(colorBufferSize, MTL::ResourceStorageModeShared);
memcpy(_vertexColorsBuffer->contents(), colors, colorBufferSize);
_vertexColorsBuffer->didModifyRange(NS::Range::Make(0, colorBufferSize));
- The bottom-left corner will be red.
- The top corner will be green.
- The bottom-right corner will be blue.
- Any pixels that exist within the interior of the triangle will contain a color that is interpolated based on that pixel's distance from each corner.
- Any pixels that exist outside of the triangle will not be re-drawn, and will contain the "clear" color, as set on our
MTK::View.
With anything in metal-cpp, I'll need to remember to release() the resources when I'm done with them. I won't be polluting the book with those calls, but forgetting to do so could be a common source of memory leaks or other types of shutdown-related errors.
The Pipeline State Object
The MTL::RenderCommandEncoder contains a setRenderPipelineState method, which takes in a pipeline state object, in the form of MTL::RenderPipelineState. Working backwards from there, I can see that pipelines are created using the MTL::Device::newRenderPipelineState method, which requires passing in a MTL::RenderPipelineDescriptor. The descriptor, in turn, requires vertex and fragment shader functions (in the form of MTL::Function objects), which are created by calling the MTL::Library::newFunction method. This method takes in a function name for the specific shader function that you wish to use within the library, but the library must first be created using the MTL::Device::newLibrary method, which takes in the source code of the shader program. That source code must be written in the aforementioned Metal Shading Language (MSL), which appears to be very similar to C++, with some additional syntax to make referencing specific parameters of the shader from the rendering API much easier.
I do this sort of reverse workflow a lot in my profession. It seems to come in handy whether I'm learning a new language, a new API, or just digging into an existing codebase for the first time. Orienting my thoughts around the goal rather than the idea of starting from scratch makes the task much less daunting, and I can quickly construct a linear theoretical path to success. One of my biggest problems is that I don't really get a kick out of writing the code if I consider the problem to have already been "solved". In this case, it is the writing of this book that is giving me forward momentum.
So let's write some shader functions. Using a combination of the metal-cpp samples, Googling for Metal shader examples, and browsing through the Metal Shading Language spec, this is what I managed to come up with:
struct VertexOutput {
float4 position [[position]];
half3 color;
};
VertexOutput vertex vertexColored(uint index [[vertex_id]],
const device float2* positions [[buffer(0)]],
const device float3* colors [[buffer(1)]]) {
VertexOutput o;
o.position = float4(positions[index], 0.0, 1.0);
o.color = half3(colors[index]);
return o;
}
half4 fragment fragmentColored(VertexOutput in [[stage_in]]) {
return half4(in.color, 1.0);
}
Eventually I want to be able to load shaders from files so that I can keep things more organized, but for now, I'll throw all of that into a multi-line string named shaderSource, and creat a MTL::Library from it. The MTL::Device::newLibrary function takes in a pointer to a NS::Error pointer (yes, a NS::Error**), which will be populated if the library itself returns a nullptr. So I'll check for the absence of the library and throw a std::runtime_error containing the error's localizedDescription(). Running the application doesn't break so far. If I change the return type of the vertexColored function to VertexOutput2, then I get the following error:
libc++abi: terminating with uncaught exception of type std::runtime_error: program_source:7:9: error: unknown type name 'VertexOutput2'; did you mean 'VertexOutput'?
VertexOutput2 vertex vertexColored(uint index [[vertex_id]],
^~~~~~~~~~~~~
VertexOutput
program_source:2:16: note: 'VertexOutput' declared here
struct VertexOutput {
^
I won't often opt to throw exceptions in a game engine, since it's preferable to just try to recover and continue rather than kick the player out of the game entirely. I've even seen fully released games with broken shaders because the runtime compilation failed for some reason. For now though, I'll just leave it as-is, since I'll be iterating on this rendering code pretty quickly.
I changed the return type back, and continued on to create my vertexFunction and fragmentFunction objects using the MTL::Library::newFunction method, which just needs the name of the function within the library that I want to use.
Next up is the creation of the MTL::RenderPipelineDescriptor, which I initialized and set the vertex and fragment functions on. All of the examples I've seen so far seem to configure the pixel format for the first color attachment on the descriptor, so I suppose I'll set that to the same pixel format as my MTK::View - MTL::PixelFormat::PixelFormatBGRA8Unorm_sRGB.
Lastly, I just need to create my MTL::RenderPipelineState using MTL::Device::newRenderPipelineState. Similar to the library creation, it also takes in a NS::Error**, so I'll check for the absence of the pipeline state object and once again throw a std::runtime_error if something went wrong.
The Triangle
All we have left to do is record our GPU commands and submit them. As I mentioned earlier (which seems like an eternity ago), we'll activate our pipeline (in Metal's terms, we'll "set the pipeline state"), and then we'll activate our buffers, and finally, we'll make a "draw" call to utilize them. I have this vague // TODO Draw stuff line from when we first got the screen to turn red. I'll replace that line with this:
renderCommandEncoder->setRenderPipelineState(_pipelineState);
renderCommandEncoder->setVertexBuffer(_vertexPositionsBuffer, 0, 0);
renderCommandEncoder->setVertexBuffer(_vertexColorsBuffer, 0, 1);
renderCommandEncoder->drawPrimitives(MTL::PrimitiveType::PrimitiveTypeTriangle, NS::UInteger(0), NS::UInteger(3));
And there you have it, a lovely triangle. I'll make a couple of quick adjustments:
- I'll set the clear color to black, because otherwise it feels like I'm writing a "Hello world" application with the wrong capitalization.
- I'll set Alfredo's window size to 375 x 667, so that it matches Scampi's
Main.storyboardview size. This will make Alfredo look more like a phone screen.
Behold! The Triangle!
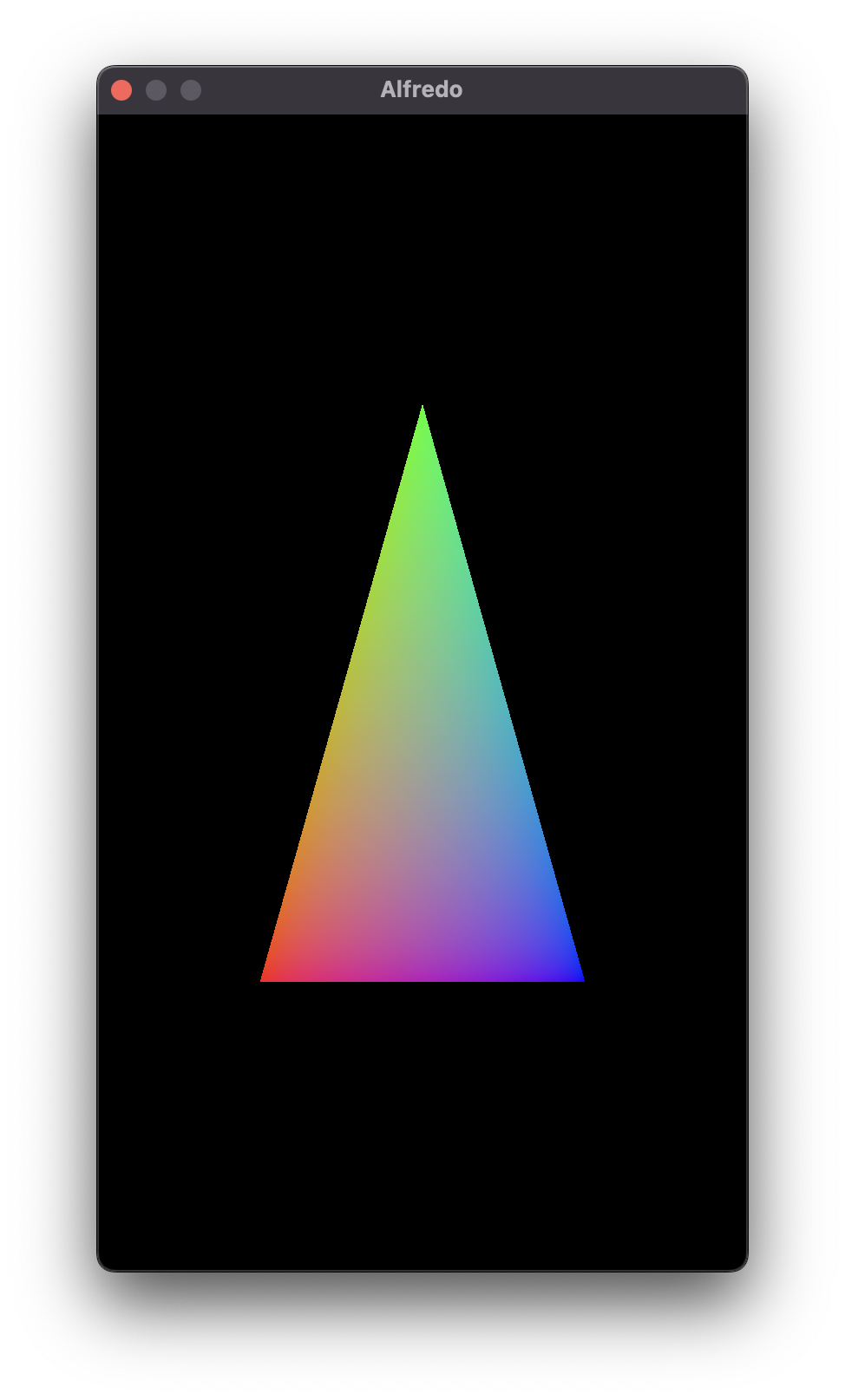
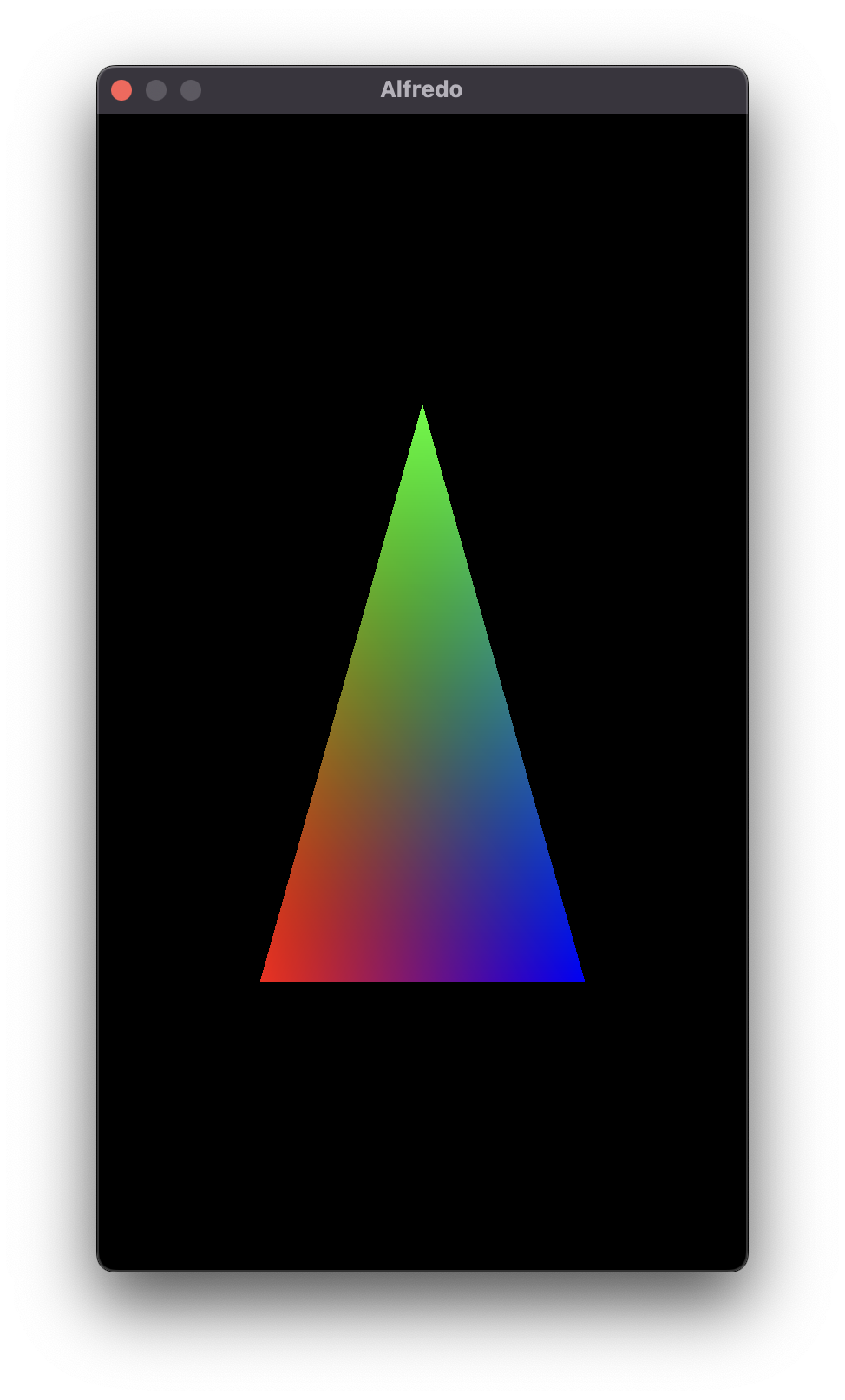
And just for kicks, let's see it in Scampi.

Getting this far with a new rendering API always reminds me of a classic meme from Parks and Recreation.

Color Spaces
You might notice that the colors in the meme are slightly different than the colors in my triangle. This is because I opted to use the sRGB color space, which I set as part of my pixel format. This is in contrast to a linear color space, which is used if I use the MTL::PixelFormat::PixelFormatBGRA8Unorm pixel format instead:
I'm definitely not an expert on digital art, but my understanding is that sRGB is almost universally used for images which are intended to be displayed to humans. What do I mean by that? Well, there exists a slew of rendering techniques which utilize textures in linear color space for the purposes of calculating some other quantity of the final image. These textures are never actually displayed to the user, but instead are loaded into GPU memory and used as data within the shaders. A common example is a texture's "normal map", which can be visualized in your image editor or debug environment, but rather than displaying it directly to the player of your game, the values within the image are sampled for the purposes of lighting calculations, which then make the final pixel lighter or darker. I'm not really sure if I'll end up using any of these types of techniques in Linguine, but I'll be sure to point it out if I do.
In any case, I'll set my color space back to sRGB and move on. Again, if you'd like to view the current state of the code, then check out the Github repository at this commit. Looking back at the beginning of this chapter, I'm happy that I was able to continue to use metal-cpp in a way that feels separate from the rest of the platform-specific code without too much bridging, or having to re-write everything in Objective-C. I'm also incredibly happy to have gotten Alfredo and Scampi to use the same renderer, which will allow me to iterate quickly, while also making sure I'm not shooting myself in the foot by using something that doesn't work on iOS (such as MTL::ResourceStorageModeManaged buffers).